VAENAR-TTS: Variational Auto-Encoder based Non-AutoRegressive Text-to-Speech Synthesis
0. Contents
- Abstract
- Comparison models and their implementations
- Synthesized samples – Comparison with other models
- Synthesized samples – Fixed reduction factors
- synthesized samples – W/ V.S. W/O causality mask
- Attention alignemnt convergence dynamics
- Other results
1. Abstract
This paper describes a variational auto-encoder based non-autoregressive text-to-speech (VAENAR-TTS) model. The autoregressive TTS (AR-TTS) models based on the sequence-to-sequence architecture can generate high-quality speech, but their sequential decoding process can be time-consuming. Recently, non-autoregressive TTS (NAR-TTS) models have been shown to be more efficient with the parallel decoding process. However, these NAR-TTS models rely on phoneme-level durations to generate a hard alignment between the text and the spectrogram. Obtaining duration labels, either through force-alignment or knowledge distillation, is cumbersome. Furthermore, hard alignment based on phoneme expansion can degrade the naturalness of the synthesized speech. In contrast, the proposed model of VAENAR-TTS is an end-to-end approach that does not require phoneme-level duration. VAENAR-TTS model does not contain recurrent structures and is completely non-autoregressive in both the training and inference phase. Based on the VAE architecture, the alignment information is encoded in the latent variable, and the attention-based soft alignment between the text and the latent variable is used in the decoder to reconstruct the spectrogram. Experiments show that VAENAR-TTS achieves state-of-the-art synthesis quality, while the synthesis speed is comparable with other NAR-TTS models.
Source Codes will be released soon!
2. Comparison models and their implementations
Below lists the implementations we used in our experiments. These models are trained and evaluated with our own dataset separation configuration, while all other settings are the default.
Tacotron2: https://github.com/NVIDIA/tacotron2
FastSpeech2: https://github.com/ming024/FastSpeech2
BVAE-TTS (official): https://github.com/LEEYOONHYUNG/BVAE-TTS
Glow-TTS (official): https://github.com/jaywalnut310/glow-tts
The below official Hifi-GAN implementation is used.
Hifi-GAN (official): https://github.com/jik876/hifi-gan
3. Synthesized samples -- Comparison with other models
Below lists the samples that are synthesized for the subjective evaluation.
LJ003-0305. The provision of more baths was also suggested, and the daily sweeping out of the prison.
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ009-0046. But the attempt fails; he trembles, his knees knock together, and his head droops as he enters the condemned pew.
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ005-0100. For this purpose it kept up an extensive correspondence with all parts of the kingdom, and circulated queries to be answered in detail,
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ006-0206. and publications which in these days would have been made the subject of a criminal prosecution.
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ007-0177. We trust, however, that the day is at hand when this stain will be removed from the character of the city of London,
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ013-0081. Banks and bankers continued to be victimized.
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ038-0009. When he heard police sirens, he, quote, looked up and saw the man enter the lobby, end quote.
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ041-0099. Powers believed that when Oswald arrived in Japan he acquired a girlfriend, quote,
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ043-0071. His performance for that company was satisfactory.
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
LJ047-0234. Hosty’s initial reaction on hearing that Oswald was a suspect in the assassination, was, quote, shock
| BVAE-TTS | FastSpeech2 | Glow-TTS | Tacotron 2 | VAENAR-TTS (ours) |
|---|---|---|---|---|
4. Synthesized samples -- Different reduction factors
Below lists samples synthesized by models with different fixed reduction factors. The evaluation results show that RF3 and RF4 are comparable and both is much better than RF5 in terms of speech naturalness
LJ003-0305. The provision of more baths was also suggested, and the daily sweeping out of the prison.
| RF5 | RF4 | RF3 |
|---|---|---|
LJ009-0046. But the attempt fails; he trembles, his knees knock together, and his head droops as he enters the condemned pew.
| RF5 | RF4 | RF3 |
|---|---|---|
LJ005-0100. For this purpose it kept up an extensive correspondence with all parts of the kingdom, and circulated queries to be answered in detail,
| RF5 | RF4 | RF3 |
|---|---|---|
LJ006-0206. and publications which in these days would have been made the subject of a criminal prosecution.
| RF5 | RF4 | RF3 |
|---|---|---|
LJ007-0177. We trust, however, that the day is at hand when this stain will be removed from the character of the city of London,
| RF5 | RF4 | RF3 |
|---|---|---|
5. synthesized samples -- W/ V.S. W/O causality mask
Below lists the samples synthesized by VAENAR-TTS with and without causality mask in the self-attention structures that are stacked on the frame-level features. The repetition issues is very common in model w/o causality mask. Pay attention to the word(s) highlighted in red color.
LJ001-0133. One very important matter in “setting up” for fine printing is the “spacing,” that is, the lateral distance of words from one another.
| W/ Causality Mask | W/O Causality Mask |
|---|---|
LJ003-0238. and they were exacted to relieve a rich corporation from paying for the maintenance of their own prison.
| W/ Causality Mask | W/O Causality Mask |
|---|---|
LJ006-0006. I shall now return to the great jail of the city of London, and give a more detailed account of its condition and inner life
| W/ Causality Mask | W/O Causality Mask* |
|---|---|
LJ009-0208. erected on the cart, about four feet high at the head, and gradually sloping towards the horse, giving a full view of the body,
| W/ Causality Mask | W/O Causality Mask |
|---|---|
LJ014-0054. a maidservant, Sarah Thomas, murdered her mistress, an aged woman, by beating out her brains with a stone.
| W/ Causality Mask | W/O Causality Mask |
|---|---|
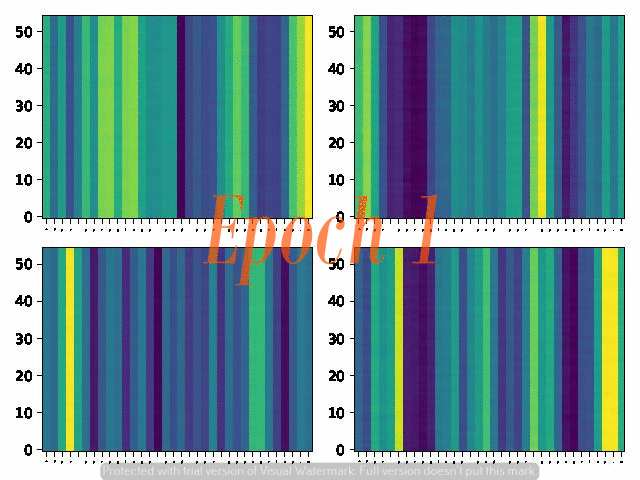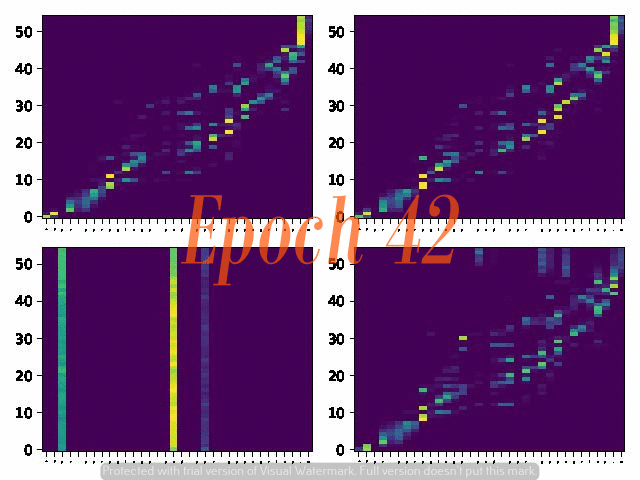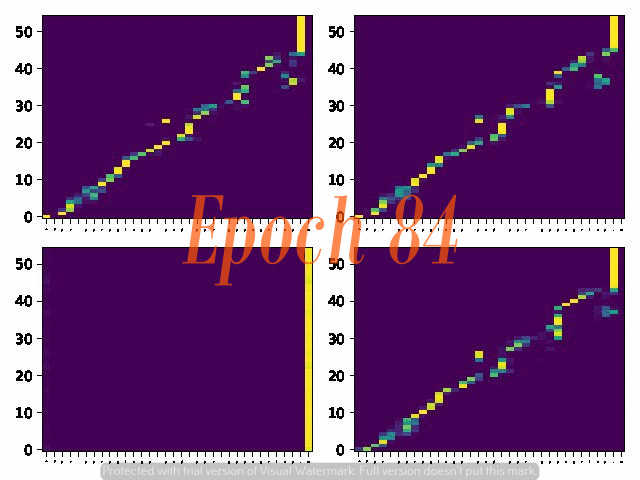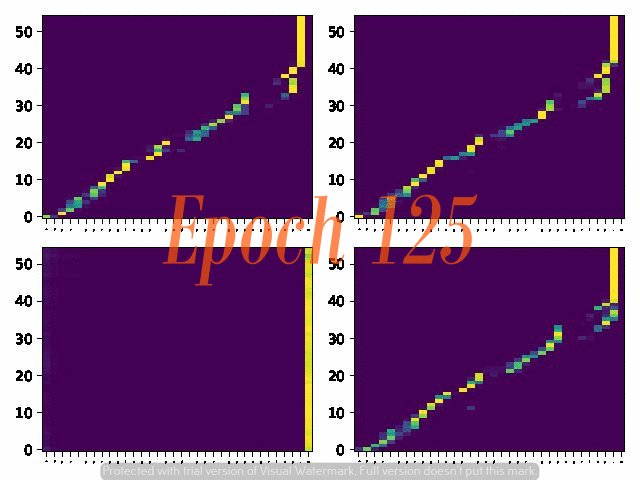
6. Attention Alignemnt convergence dynamics
Below are the attention alignment maps obtained during the training process of three models with different fixed reduction factors: 5, 4, and 3. Note that the alignment converges faster for the model with a larger reduction factor.
Reduction factor = 3
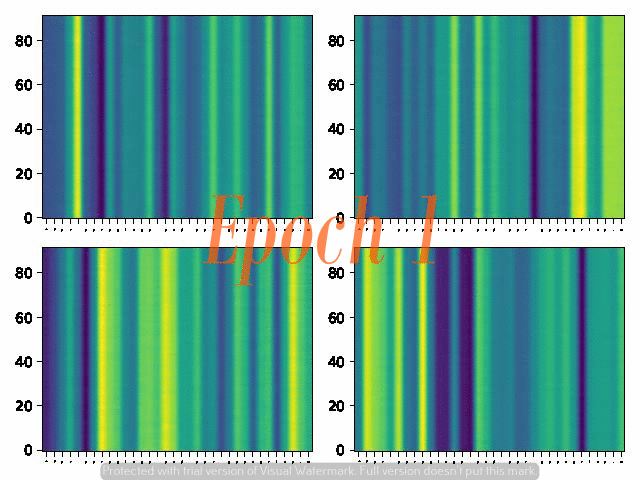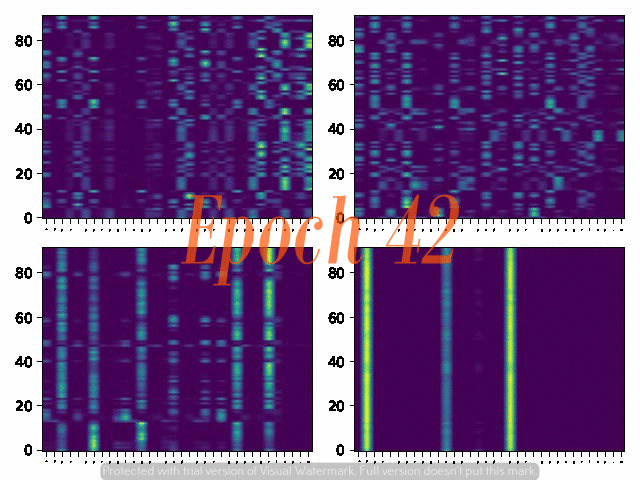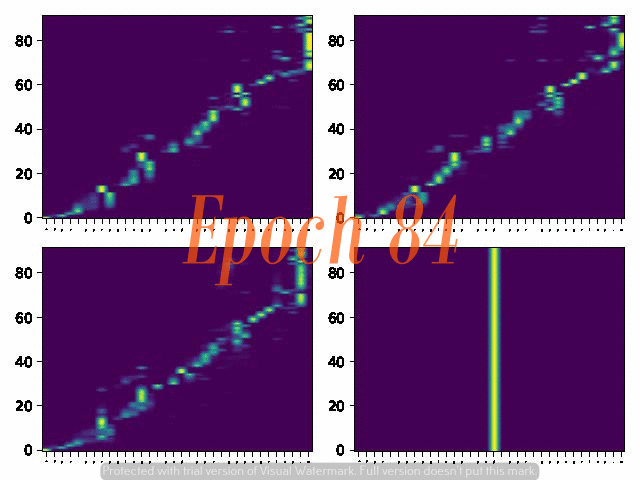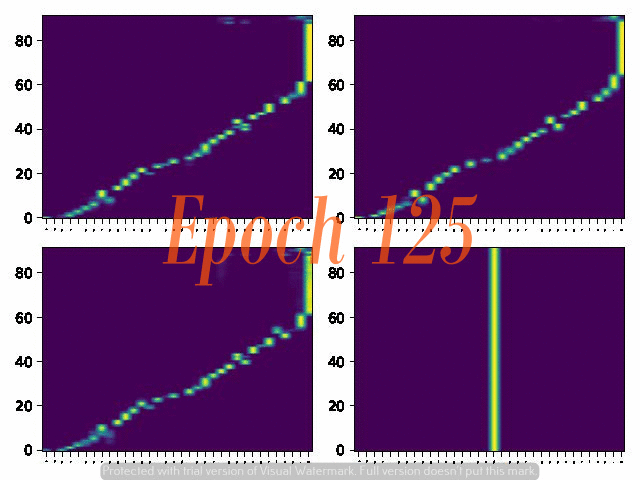
Reduction factor = 4
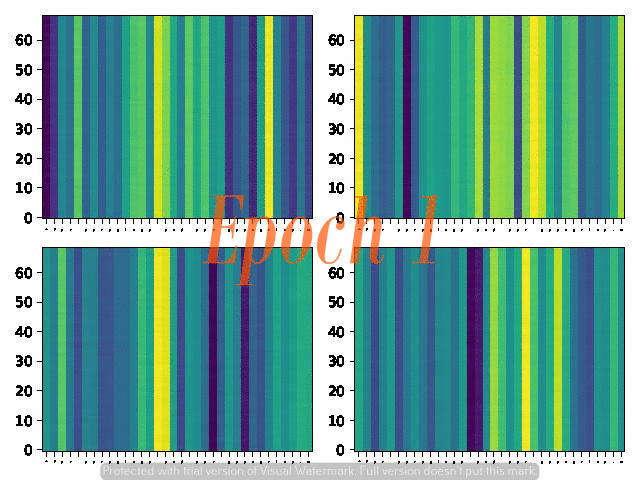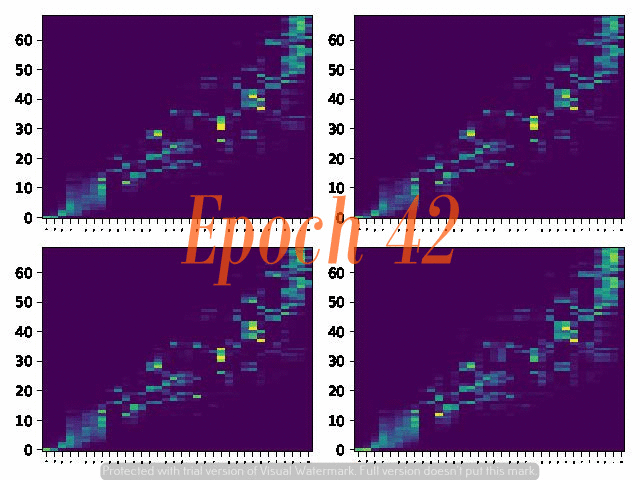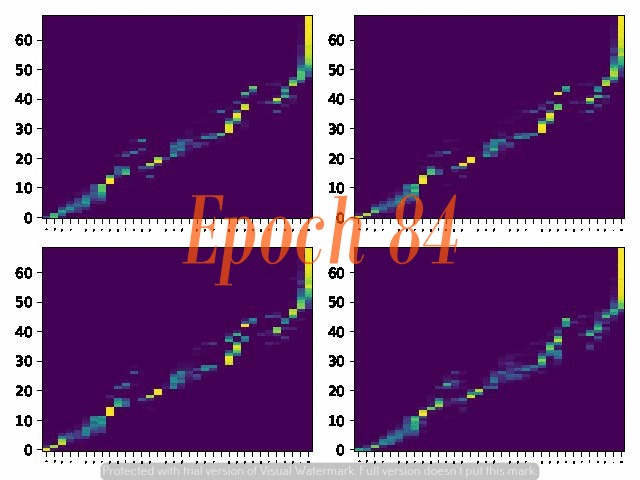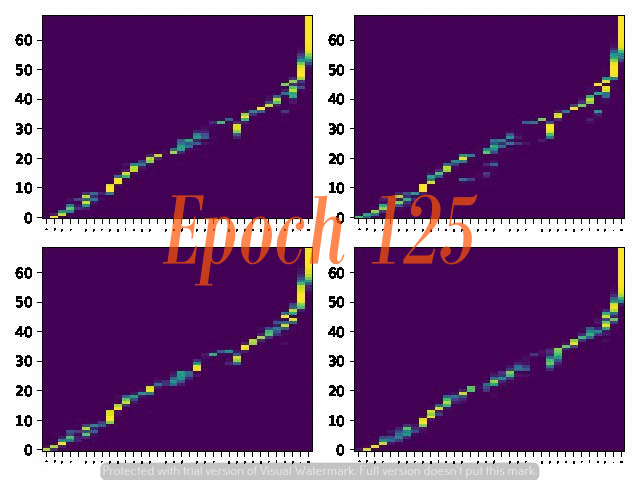
Reduction factor = 5
7. Other results
Synthesized results in Madarin
Trained on dataset DataBaker.
003095.失恋的人特别喜欢往人烟罕至的角落里钻。
003684.天安门广场,一派春意盎然。
004539.网友“甄巍峰”说,希望规范用工制度和用工秩序。
005134.我的性格也是逆来顺受,从小胆小怕事,凡事都忍让。
007732.乘客对车上负责讲解的导乘员普遍表示满意。